A lot has changed since I wrote the article Introduction to BentoML: A Unified AI Application Framework, both in the general AI landscape and in BentoML. Generative AI, large language models, diffusion models, ChatGPT (Sora) and Gemma: these are probably the most talked about terms in the last few months in AI, and the speed of change is incredible. Amidst these brilliant AI breakthroughs, the quest for AI implementation tools that are not only powerful, but also easy to use and cost-effective remains unchanged. For BentoML, it comes with a major update 1.2, which goes towards the same goal.
In this blog post, let’s go back to BentoML and use a simple example to see how we can take advantage of some of the new tools and functionality offered by BentoML to build an AI application in production.
The example app I’m going to build is capable of adding captions to images, which involves generating a text description of the image using artificial intelligence. BLIP (Bootstrapping Language-Image Pre-training) is a method that improves these AI models by initially training them on large image and text datasets to understand their relationship, and then further refining this understanding using specific tasks such as description. The BLIP model I will be using in the sections below is Salesforce/blip-image-captioning-large. You can use any other BLIP model for this example as the code implementation logic is the same.
A quick introduction
Before we go deeper, let’s highlight what BentoML brings to the table, especially with its 1.2 update. At its core, BentoML is an open source platform designed to simplify serving and deploying AI applications. Here’s a simplified workflow with BentoML 1.2:
- Model wrapping: Use the BentoML Service SDKs to wrap your machine learning model so that you can expose it as an inference endpoint.
- Model serving: Run the model on your own computer, using your own resources (like GPUs) to infer the model through the endpoint.
- Simple implementation: Deploy your model on the BentoCloud serverless platform.
For the final step, we previously had to manually build Bento (a unified distribution unit in BentoML that contains the source code, Python packages, and model reference and configuration), then push and deploy it to BentoCloud. With BentoML 1.2, “Build, Push, and Deploy” are now consolidated into a single command bentoml deploy. I’ll talk more about the details and BentoCloud in the example below.
Note: If you want to deploy the model to your own infrastructure, you can still do so by manually building Bento and then saving it to the container as an OCI-compatible image.
Now, let’s start seeing how this works in practice!
Setting up the environment
Create a virtual environment with venv. This is recommended as it helps avoid possible packet conflicts.
python -m venv bentoml-new
source bentoml-new/bin/activate
Install all dependencies.
pip install "bentoml>=1.2.2" pillow torch transformers
Building a BentoML service
First, import the required packages and use a constant to store the model ID.
from __future__ import annotations
import typing as t
import bentoml
from PIL.Image import Image
MODEL_ID = "Salesforce/blip-image-captioning-large"Next, let’s create the BentoML service. For versions prior to BentoML 1.2, we use abstractions called “Runners” to infer models. In 1.2, BentoML works on this Runner concept by integrating API server and Runner functionality into a single unit called “Services”. They are the key building blocks for defining model serving logic in BentoML.
Starting with 1.2, we use @bentoml.service decorator to mark the Python class as a BentoML service in a file named service.py. For this BLIP example, we can create a service called BlipImageCaptioning like this:
@bentoml.service
class BlipImageCaptioning:
During initialization, what we usually do is load the model (and other components if needed) and move them to the GPU for better computational efficiency. If you’re not sure which function or package to use, simply copy and paste the initialization code from the BLIP Hugging Face repo. Here’s an example:
@bentoml.service
class BlipImageCaptioning:
def __init__(self) -> None:
import torch
from transformers import BlipProcessor, BlipForConditionalGeneration
# Load the model with torch and set it to use either GPU or CPU
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model = BlipForConditionalGeneration.from_pretrained(MODEL_ID).to(self.device)
self.processor = BlipProcessor.from_pretrained(MODEL_ID)
print("Model blip loaded", "device:", self.device)
The next step is to create an endpoint function for user interaction @bentoml.api. When applied to a Python function, it transforms that function into an API endpoint that can process web requests.
This BLIP model can take an image and optionally some initial text for the description, so I defined it this way:
@bentoml.service
class BlipImageCaptioning:
...
@bentoml.api
async def generate(self, img: Image, txt: t.Optional[str] = None) -> str:
if txt:
inputs = self.processor(img, txt, return_tensors="pt").to(self.device)
else:
inputs = self.processor(img, return_tensors="pt").to(self.device)
# Generate a caption for the given image by processing the inputs through the model, setting a limit on the maximum and minimum number of new tokens (words) that can be added to the caption.
out = self.model.generate(**inputs, max_new_tokens=100, min_new_tokens=20)
# Decode the generated output into a readable caption, skipping any special tokens that are not meant for display
return self.processor.decode(out[0], skip_special_tokens=True)
The generate A method inside a class is an asynchronous function exposed as an API endpoint. Receives an image and an option txt parameter, processes them with the BLIP model and returns the generated title. Note that the main inference code also comes from the Hugging Face reposition of the BLIP model. BentoML just helps you manage the input and output logic here.
That’s all the code! Full version:
from __future__ import annotations
import typing as t
import bentoml
from PIL.Image import Image
MODEL_ID = "Salesforce/blip-image-captioning-large"
@bentoml.service
class BlipImageCaptioning:
def __init__(self) -> None:
import torch
from transformers import BlipProcessor, BlipForConditionalGeneration
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model = BlipForConditionalGeneration.from_pretrained(MODEL_ID).to(self.device)
self.processor = BlipProcessor.from_pretrained(MODEL_ID)
print("Model blip loaded", "device:", self.device)
@bentoml.api
async def generate(self, img: Image, txt: t.Optional[str] = None) -> str:
if txt:
inputs = self.processor(img, txt, return_tensors="pt").to(self.device)
else:
inputs = self.processor(img, return_tensors="pt").to(self.device)
out = self.model.generate(**inputs, max_new_tokens=100, min_new_tokens=20)
return self.processor.decode(out[0], skip_special_tokens=True)
To serve this model locally, run:
bentoml serve service:BlipImageCaptioning
The HTTP server is available at http://localhost:3000. You can interact with it using the Swagger UI.
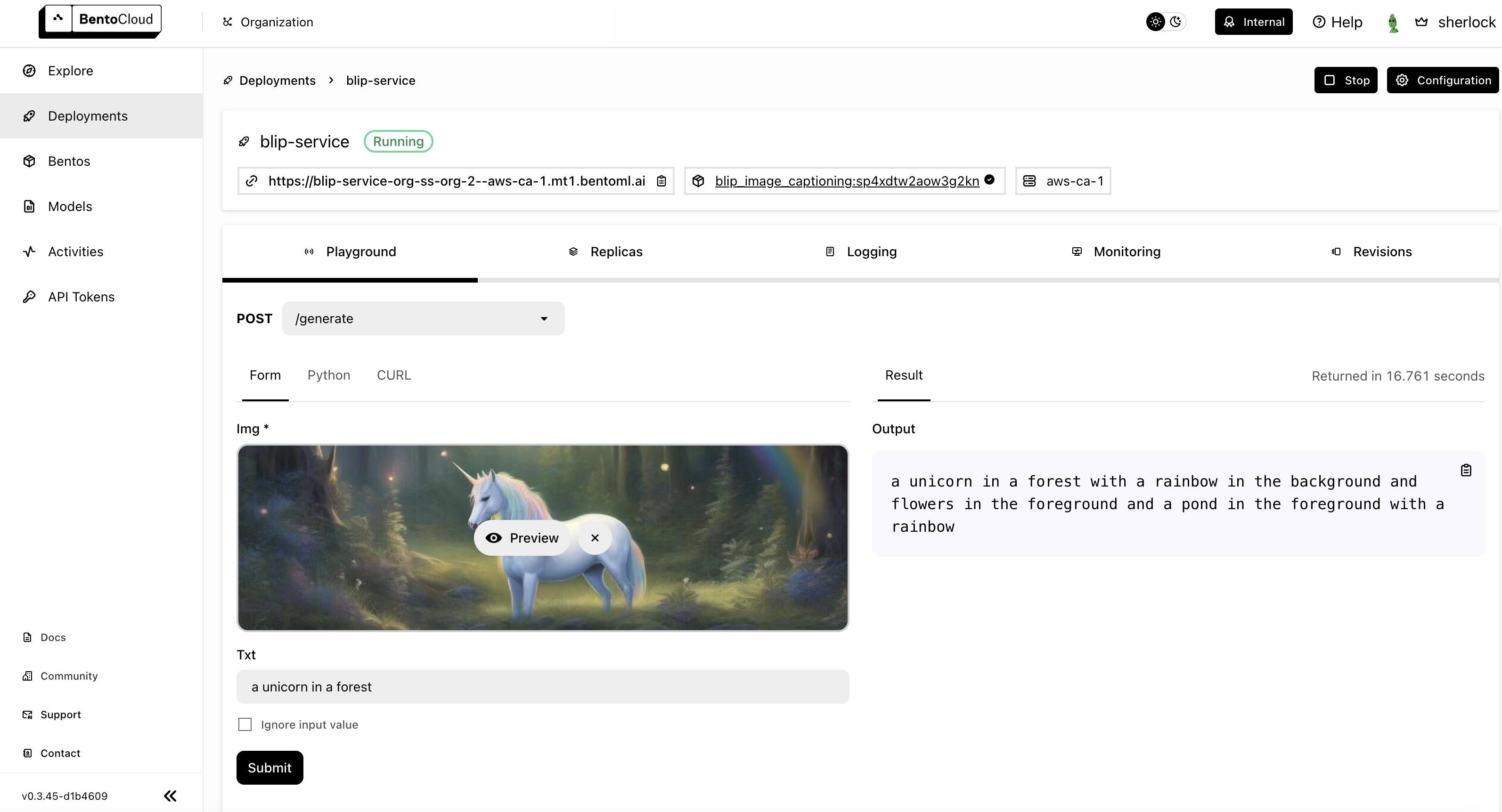
I loaded the image below (I created this image using Stable Diffusion and it was also uploaded using BentoML) and used the query text “unicorn in the forest” to infer.

The description of the image created by the model was: a unicorn in a forest with a rainbow in the background and flowers in the foreground and a pond in the foreground with a rainbow.
Local serving works fine, but there are various things we always have to consider for deploying AI applications in production, such as infrastructure (especially GPUs), scaling, visibility, and cost-effectiveness. This is where BentoCloud comes into play.
Implementation in BentoCloud
Explaining BentoCloud may require an independent blog post. Here’s an overview of what it offers and how you can leverage it for your machine learning implementation:
- Auto-scaling for ML workloads: BentoCloud dynamically scales deployment replicas based on incoming traffic, scaling down to zero during periods of inactivity to optimize costs.
- Built-in observation capability: Access real-time insights into your traffic, monitor resource utilization, monitor operational events, and view audit logs directly through the BentoCloud console.
- Optimized infrastructure. With BentoCloud, the focus shifts entirely to code development as the platform manages all the underlying infrastructure, ensuring an optimized environment for your AI applications.
To prepare your BentoML service for BentoCloud deployment, start by defining it resources field in your Service Code. This tells BentoCloud how to allocate the appropriate instance type for your service. See Configurations for details.
@bentoml.service(
resources=
"memory" : "4Gi"
)
class BlipImageCaptioning:
Then create a bentofile.yaml file to define build options, used to build Bent. Again, when you use BentoCloud, you don’t need to build Bento manually, because BentoML does it automatically for you.
service: "service:BlipImageCaptioning"
labels:
owner: bentoml-team
project: gallery
include:
- "*.py"
python:
packages:
- torch
- transformers
- pillow
Deploy your service on BentoCloud using bentoml deploy command and use -n flag to assign a custom name to your implementation. Don’t forget to register beforehand.
bentoml deploy . -n blip-service
Deployment involves a series of automated processes where BentoML builds Bento and then pushes and deploys it to BentoCloud. You can see the status displayed on your terminal.

All ready! Once deployed, you can find the deployment in the BentoCloud console, which provides a comprehensive interface, offering an enhanced user experience for interacting with your service.
Conclusion
BentoML 1.2 significantly simplifies AI implementation, enabling developers to easily bring AI models into production. Its integration with BentoCloud offers scalable, efficient solutions. In future blog posts, I’ll show how to build more production-ready AI applications for different scenarios. Happy coding!