Distributed databases partition data across several nodes, spreading across regions depending on the database configuration. Such a partition is fundamental for achieving scalability. All such cloud-native databases have some kind of session management layer. A session, in simple terms, is a range of communication between a database client and a server. It can include multiple transactions. That is, in a certain session, the client can write and read a lot. The session management layer is usually responsible for guaranteeing “read own records”. That is, the data written by the user must be available for reading in the same session.
Session consistency
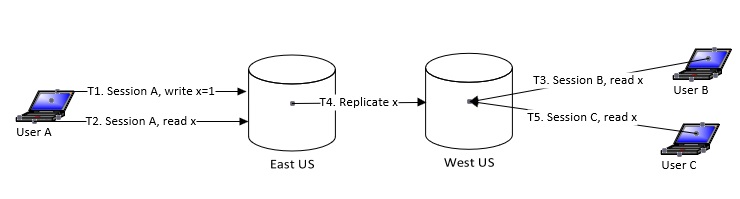
In a distributed database world, with many regions serving the database, reads can happen from anywhere. Basically there is a need to distinguish between “Not Found” and “Not Available” scenarios. That is, in the first case the data does not exist, while in the second case the data has yet to be seen by the region. This is important to ensure the “read your own writing” guarantee. For example, let’s look at the time steps that occur in the image below.
- T1: User A using session A records the value of x as 1.
- T2: User A using the same session A tries to read the value of x. The output returned will be 1.
- T3: User B in session B reads the value of x, but will get “Not Found” because the US West region has not yet seen the data.
- T4: The x value is replicated from the US East to the US West region.
- T5: User C in session C when reading the value of x will now see the value as 1.
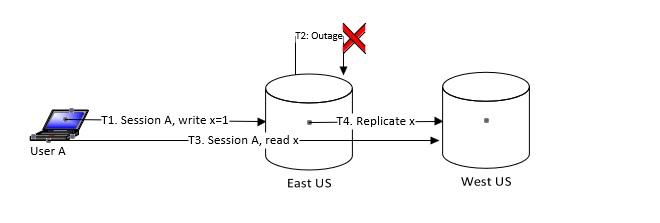
Now let’s look at the outage scenario, as shown in the image below.
- T1: User A using session A records the value of x as 1.
- T2: The outage is happening in US East and user A is unable to connect to US East.
- T3: A user using the same session A tries to read the value of x. Now the call can be routed to another available region (US West). Note that replication is not complete. So, the user should not get “Not Found.” Otherwise, the “read your own writing” guarantee would be violated.
Session Token
In the outage example shown above, one might wonder what the West US region should do in this case. There are two subproblems:
- How does a region know it can’t return “Not Found”?
- Alternatively, what action should it take if it cannot return “Not Found”?
This is where session tokens come in handy. The session token contains information about the progress of the region. In the example above, Session A saw a larger advance than the US West. In this case, by reviewing the session token, the West US region may determine that it is lagging behind and cannot serve this request. Instead, it can redirect the request back to US East. In this case, the session token might look like “[East US: 1, West US:0]”, meaning that the US East advanced by one operation and the US West saw no operations. In general, a typical session token breakdown will look like this:
Session token = “region1:progress1, region2:progress2 …”
Conclusion
In conclusion, session management in distributed databases is fundamental to ensuring data consistency. Different databases might implement session tokens differently than what is described here, but they are basically designed to provide “read your own writing” guarantees. In addition, the session token can also encode additional information, for example, if it has partition information, then the request can be routed to the correct partition within the same region.
Further reading
- The MongoDB Handbook
- Microsoft Azure Cosmos
- Amazon Dynamo DB