In DolphinDB, we can import historical data into the flow table in chronological order as “real-time data” so that the same script can be used for both backtesting and real-time trading. As for streaming to DolphinDB, take a look Guide to DolphinDB Streaming.
This article introduces functions replay and replayDS and then demonstrates the data reproduction process.
1. Functions
replay
replay(inputTables, outputTables, [dateColumn], [timeColumn], [replayRate], [absoluteRate=true], [parallelLevel=1])
Function replay inserts data from specified tables or data sources into flow tables.
‘inputTables’is a table or tuple. Each element of the tuple is a non-partitioned table or data source generated by the functionreplayDS.‘outputTables’is a table or a tuple of tables, or a string or a string vector. Number of elements ofoutputTablesmust be equal to the number of elementsinputTables. If it is a vector, it is a list of the names of the common stream tables where the data of the corresponding tables is reproducedinputTablesare saved. If it is a tuple, each element is a shared stream table containing the replayed data of the corresponding tableinputTablesare saved. The scheme of each table inoutputTablesmust be identical to the schema of the corresponding table ininputTables.‘dateColumn’and‘timeColumn’are strings indicating the date column and the time column in the inputTables. If none is specified, the first column of the table is selected as‘dateColumn’. If it exists‘dateColumn’, it must be one of the partition columns. Only if‘timeColumn’specified, it must be one of the partition columns. If the date and time information comes from the same column (eg DATETIME, TIMESTAMP), use the same column for both‘dateColumn’and‘timeColumn’. Data is reproduced in batches determined by the smallest unit of time u‘timeColumn’or‘dateColumn’if‘timeColumn’not specified. For example, if the smallest unit of time is u‘timeColumn’is the second, then all data in the same second are reproduced in the same series; if‘timeColumn’is not specified, then all data in the same day are replayed in the same series.‘replayRate’is a non-negative integer indicating the number of lines replayed per second. If not specified, it means that the data is played at maximum speed.‘replayRate’is an integer.‘absoluteRate’is a Boolean value. The default value is true.
Regarding ‘replayRate’ and ‘absoluteRate’:
- If
‘replayRate‘ is a positive integer iabsoluteRate=trueplay at a speed of‘replayRate’lines per second. - If
‘replayRate’is a positive integer iabsoluteRate=falsereplay on‘replayRate’times the original data rate. For example, if the difference between the maximum and minimum values of‘dateColumn’or‘timeColumn’is n seconds, then it is necessaryn/replayRateseconds to end the replay. - if’
replayRate’is indeterminate or negative, play at maximum speed.‘parallelLevel’is a positive integer. When the size of individual partitions in data sources is too large compared to the size of memory, we have to use a functionreplayDSto further divide individual partitions into smaller data sources.'parallelLevel'indicates the number of threads simultaneously loading data into memory from these smaller data sources. The default value is 1. If'inputTables'is a table or set of tables, effective'parallelLevel'is always 1.
replayDS
replayDS(sqlObj, [dateColumn], [timeColumn], [timeRepartitionSchema])
Function replayDS generates a group of data sources to be used as function inputs replay. Splits an SQL query into multiple subqueries based on 'timeRepartitionSchema' with 'timeColumn' within each 'dateColumn' septum.
‘sqlObj’is a table or metacode with SQL statements (such as<select * from sourceTable>) indicating the data to be replayed. The “select from” table object must use a column of type DATE as one of the partitioning columns.‘dateColumn’and‘timeColumn’are strings indicating a date column and a time column. If none is specified, the first column of the table is selected as‘dateColumn’. If it exists‘dateColumn’, it must be one of the partition columns. Only if‘timeColumn’specified, it must be one of the partition columns. If the date and time information comes from the same column (eg DATETIME, TIMESTAMP), use the same column for both‘dateColumn’and‘timeColumn’. FunctionreplayDSand the corresponding functionreplaymust use the same set'dateColumn'and'timeColumn'.‘timeRepartitionSchema’is a TIME or NANOTIME type vector.‘timeRepartitionSchema’delimits multiple data sources on a dimension‘timeColumn’within each‘dateColumn’septum. For example, if timeRepartitionSchema=[t1, t2, t3]then there are 4 data sources within a day: [00:00:00.000,t1), [t1,t2), [t2,t3) and [t3,23:59:59.999).
Replay a Single In-Memory Table
replay(inputTable, outputTable, `date, `time, 10)
Replay a Single Table Using Data Sources
To replay a single table with a large number of rows, we can use function replayDS together with function replay. Function replayDSdeliminates multiple data sources on the dimension of 'timeColumn' within each 'dateColumn' partition. Parameter 'parallelLevel' of functionreplay` specifies the number of threads loading data into memory from these smaller data sources simultaneously. In this example, ‘parallelLevel’ is set to 2.
inputDS = replayDS(<select * from inputTable>, `date, `time, 08:00:00.000 + (1..10) * 3600000)
replay(inputDS, outputTable, `date, `time, 1000, true, 2)
Replay Multiple Tables Simultaneously Using Data Sources
To replay multiple tables simultaneously, assign a tuple of these table names to the parameter ‘inputTables’ of the function replay and specify the output tables. Each of the output tables corresponds to an input table and should have the same schema as the corresponding input table. All input tables should have identical 'dateColumn' and 'timeColumn'.
ds1 = replayDS(<select * from input1>, `date, `time, 08:00:00.000 + (1..10) * 3600000)
ds2 = replayDS(<select * from input2>, `date, `time, 08:00:00.000 + (1..10) * 3600000)
ds3 = replayDS(<select * from input3>, `date, `time, 08:00:00.000 + (1..10) * 3600000)
replay([ds1, ds2, ds3], [out1, out2, out3]`date, `time, 1000, true, 2)
Cancel replay
If the function replay he was invited with submitJobwe can use getRecentJobs to get the jobId, then undo the playback with the command cancelJob.
getRecentJobs()
cancelJob(jobid)
If the function replay called directly, we can use getConsoleJobs in another GUI session to get the jobId, then cancel the replay and use the command cancelConsoleJob.
getConsoleJobs()
cancelConsoleJob(jobId)
2. How to use the reproduced data
The replayed data is streaming data. We may subscribe to and process reproduced data in the following 3 ways:
- Subscribe to DolphinDB. Write user-defined functions in DolphinDB to process data streams.
- Subscribe to DolphinDB. For real-time calculations with streaming data, use DolphinDB’s built-in streaming aggregators such as the time series aggregator, cross section aggregator, and anomaly detection engine. They are very easy to use and have excellent performance. In Section 3.2, we use a cross-sectional aggregator to calculate the intrinsic value of an ETF.
- With third-party clients via DolphinDB’s streaming API.
3. Examples
Replay the Level 1 stock quotes to calculate the ETF’s intrinsic value.
In this example, we repeat the level 1 stock quotes on the US stock exchanges on 2007/08/17 and calculate the intrinsic value of the ETF with the built-in cross-sectional aggregator in DolphinDB. The following is the schema of the input table ‘quotes’ and the overview of the data.
quotes = database("dfs://TAQ").loadTable("quotes");
quotes.schema().colDefs;
select top 10 * from quotes where date=2007.08.17
1. To play a large amount of data, if we load all the data into memory first, we might have a memory shortage problem. First we can use a function replayDS and specify the parameter 'timeRepartitionSchema' split the data into 60 parts based on the ‘time’ column.
trs = cutPoints(09:30:00.000..16:00:00.000, 60)
rds = replayDS(<select * from quotes where date=2007.08.17>, `date, `time, trs);
2. Define the output flow table ‘outQuotes’.
sch = select name,typeString as type from quotes.schema().colDefs
share streamTable(100:0, sch.name, sch.type) as outQuotes
3. Define the vocabulary for the weight and function of ETF components etfVal to calculate the intrinsic value of the ETF. For simplicity, we use an ETF with only 6 stocks.
defg etfVal(weights,sym, price)
return wsum(price, weights[sym])
weights = dict(STRING, DOUBLE)
weights[`AAPL] = 0.1
weights[`IBM] = 0.1
weights[`MSFT] = 0.1
weights[`NTES] = 0.1
weights[`AMZN] = 0.1
weights[`GOOG] = 0.5
4. Define a stream aggregator to subscribe to the output stream table ‘outQuotes’. We specify a filtering condition for the subscription that only data with the stock symbols AAPL, IBM, MSFT, NTES, AMZN or GOOG is published in the aggregator. This significantly reduces unnecessary network load and data transfer.
setStreamTableFilterColumn(outQuotes, `symbol)
outputTable = table(1:0, `time`etf, [TIMESTAMP,DOUBLE])
tradesCrossAggregator=createCrossSectionalAggregator("etfvalue", <[etfValweights(symbol, ofr)]>, quotes, outputTable, `symbol, `perBatch)
subscribeTable(tableName="outQuotes", actionName="tradesCrossAggregator", offset=-1, handler=append!tradesCrossAggregator, msgAsTable=true, filter=`AAPL`IBM`MSFT`NTES`AMZN`GOOG)
5. Begin replaying the data at the specified rate of 100,000 lines per second. The streaming aggregator performs real-time calculations with replayed data.
submitJob("replay_quotes", "replay_quotes_stream", replay, [rds], [`outQuotes], `date, `time, 100000, true, 4)
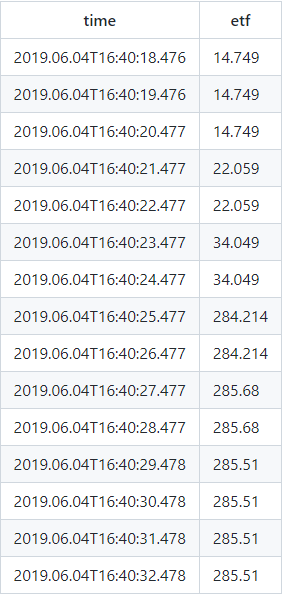
6. Check the intrinsic values of the ETF
select top 15 * from outputTable
4. Performance testing
We tested data playback in DolphinDB on a server with the following configuration:
- Server: DELL PowerEdge R730xd
- CPU: Intel Xeon(R) CPU E5–2650 v4 (24 cores, 48 threads, 2.20 GHz)
- RAM: 512 GB (32 GB × 16, 2666 MHz)
- Hard disk: 17T HDD (1.7T × 10, read speed 222 MB/s, write speed 210 MB/s)
- Network: 10 Gigabit Ethernet
DolphinDB script:
sch = select name,typeString as type from quotes.schema().colDefs
trs = cutPoints(09:30:00.000..16:00:00.001,60)
rds = replayDS(<select * from quotes where date=2007.08.17>, `date, `time, trs);
share streamTable(100:0, sch.name, sch.type) as outQuotes1
jobid = submitJob("replay_quotes","replay_quotes_stream", replay, [rds], [`outQuotes1], `date, `time, , ,4)
When playing at maximum speed (parameter ‘replayRate’ not specified) The output table is not subscribed and only takes about 100 seconds to replay 336,305,414 rows of data.