In this blog, you will learn how to implement Retrieval Augmented Generation (RAG) using Weaviate, LangChain4j and LocalAI. This implementation allows you to ask questions about your documents using natural language. To enjoy!
1. Introduction
In the previous post, Weaviate was used as a vector database to perform semantic search. The source documents used are two Wikipedia documents. The discography and list of songs recorded by Bruce Springsteen are the documents used. The interesting thing about these documents is that they contain facts and that they are mostly in tabular form. Parts of these documents are converted to Markdown for better display. Markdown files are embedded in collections in Weaviate. The result was amazing: all the questions asked resulted in a correct answer to the question. That is, the correct segment is returned. You still had to work out the answer yourself, but this was pretty easy.
However, can this be solved by providing the Weaviate search results to the LLM (Large Language Model) by creating the right prompt? Will the LLM be able to extract the correct answers to the questions?
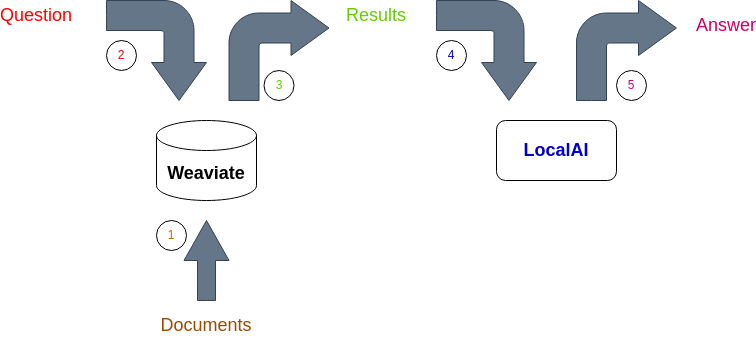
The setup is visualized in the chart below:
- Documents are embedded and stored in Weaviate;
- The question is embedded and the semantic search is performed using Weaviate;
- Weaviate returns semantic search results;
- The result is added to the query and sent to LocalAI which runs LLM using LangChain4j;
- LLM returns the answer to the question.
Weaviate also supports RAG, so why bother using LocalAI and LangChain4j? Unfortunately, Weaviate does not support integration with LocalAI and only cloud LLMs can be used. If your documents contain sensitive information or information that you don’t want to send to a cloud-based LLM, you need to run a local LLM, and this can be done using LocalAI and LangChain4j.
If you want to run the examples on this blog, you must read the previous blog.
The sources used in this blog can be found on GitHub.
2. Prerequisites
The prerequisites for this blog are:
- Basic knowledge of embedding and vector storage;
- Basic knowledge of Java, Java 21 is used;
- Basic knowledge of Docker;
- Basic knowledge of LangChain4j;
- You need Weaviate and the docs must be embedded, see the previous blog on how to do this;
- You need LocalAI to run the examples, see the previous blog on how you can use LocalAI. Version 2.2.0 is used for this blog.
- If you want to know more about RAG, read this blog.
3. Create settings
Before you start, you need to make some settings.
3.1 Local AI setup
LocalAI must be running and configured. How to do this is explained in the blog Running LLM’s Locally: A Step-by-Step Guide.
3.2 Setting up Weaviata
Weaviate must be started. The only difference with the Weaviate blog is that you will be running it on port 8081 instead of port 8080. This is because LocalAI already runs on port 8080.
Run the build file from the root of the repository.
$ docker compose -f docker/compose-embed-8081.yamlRun the EmbedMarkdown class to embed the documents (change the port to 8081!). Three collections were created:
- CompilationAlbum: list of all Bruce Springsteen compilation albums;
- A song: list of all Bruce Springsteen songs;
- Studio album: list of all Bruce Springsteen studio albums.
4. Implement RAG
4.1 Semantic search
The first part of the implementation is based on the semantic search implementation of the SearchCollectionNearText class. Here it is assumed that you know in which collection (argument className) to look for.
You noted in the previous post that, strictly speaking, you don’t need to know which collection you’re looking for. However, at this point it makes implementation a bit easier, and the result remains identical.
The code will take the question and with help NearTextArgument, the question will be embedded. Weaviate’s GraphQL API is used to perform searches.
private static void askQuestion(String className, Field[] fields, String question, String extraInstruction) {
Config config = new Config("http", "localhost:8081");
WeaviateClient client = new WeaviateClient(config);
Field additional = Field.builder()
.name("_additional")
.fields(Field.builder().name("certainty").build(), // only supported if distance==cosine
Field.builder().name("distance").build() // always supported
).build();
Field[] allFields = Arrays.copyOf(fields, fields.length + 1);
allFields[fields.length] = additional;
// Embed the question
NearTextArgument nearText = NearTextArgument.builder()
.concepts(new String[]question)
.build();
Result<GraphQLResponse> result = client.graphQL().get()
.withClassName(className)
.withFields(allFields)
.withNearText(nearText)
.withLimit(1)
.run();
if (result.hasErrors())
System.out.println(result.getError());
return;
...4.2 Create an inquiry
The result of the semantic search should be submitted to LLM, including the question itself. A query is created that will instruct the LLM to answer the question using the semantic search results. Also, the option of adding additional instructions has been implemented. You’ll see what to do with it later.
private static String createPrompt(String question, String inputData, String extraInstruction)
return "Answer the following question: " + question + "\n" +
extraInstruction + "\n" +
"Use the following data to answer the question: " + inputData;
4.3 Use LLM
The last thing you need to do is send a prompt to LLM and print the question and answer to the console.
private static void askQuestion(String className, Field[] fields, String question, String extraInstruction)
...
ChatLanguageModel model = LocalAiChatModel.builder()
.baseUrl("http://localhost:8080")
.modelName("lunademo")
.temperature(0.0)
.build();
String answer = model.generate(createPrompt(question, result.getResult().getData().toString(), extraInstruction));
System.out.println(question);
System.out.println(answer);
4.4 Questions
The questions asked are the same as in the previous posts. They will call the code above.
public static void main(String[] args)
askQuestion(Song.NAME, Song.getFields(), "on which album was \"adam raised a cain\" originally released?", "");
askQuestion(StudioAlbum.NAME, StudioAlbum.getFields(), "what is the highest chart position of \"Greetings from Asbury Park, N.J.\" in the US?", "");
askQuestion(CompilationAlbum.NAME, CompilationAlbum.getFields(), "what is the highest chart position of the album \"tracks\" in canada?", "");
askQuestion(Song.NAME, Song.getFields(), "in which year was \"Highway Patrolman\" released?", "");
askQuestion(Song.NAME, Song.getFields(), "who produced \"all or nothin' at all?\"", "");
You can see the full source code here.
5. Results
Run the code and the output is as follows:
- What album was “Adam Raised a Cain” originally released on?
The album “Darkness on the Edge of Town” was originally released in 1978, and the song “Adam Raised a Cain” was on that album. - What is the highest ranking position of “Greetings from Asbury Park, NJ” in the USA?
The highest ranking position of “Greetings from Asbury Park, NJ” in the USA is 60. - What is the highest position of the album “Tracks” in Canada?
Based on the above data, the highest position on the “Tracks” album chart in Canada is -. This is because the data does not include Canadian chart positions for this album. - What year was “Highway Patrolman” released?
The song “Highway Patrolman” was published in 1982. - Who produced “all or nothing?”
The song “All or Nothin’ at All” was produced by Bruce Springsteen, Roy Bittan, Jon Landau and Chuck Plotkin.
All the answers to the questions are correct. The most important work was done in the previous post, where inserting the documents in the correct way resulted in finding the correct segments. LLM is able to derive the answer to the question when it gets the correct data.
6. Warnings
During the implementation I encountered some strange behavior which is very important to know when starting to implement your use case.
6.1 Format of Weaviate results
Weaviate’s answer contains a GraphQLResponse object, something like the following:
GraphQLResponse(
data=
Get=
Songs=[
_additional=certainty=0.7534831166267395, distance=0.49303377,
originalRelease=Darkness on the Edge of Town,
producers=Jon Landau Bruce Springsteen Steven Van Zandt (assistant),
song="Adam Raised a Cain", writers=Bruce Springsteen, year=1978
]
,
errors=null)In the code, the data part is used to add to the query.
String answer = model.generate(createPrompt(question, result.getResult().getData().toString(), extraInstruction));What happens when you add an as-is answer to a query?
String answer = model.generate(createPrompt(question, result.getResult().toString(), extraInstruction));Running the code returns the following incorrect answer for question 3 and some unnecessary additional information for question 4. The other questions were answered correctly.
- What is the highest position of the album “Tracks” in Canada?
Based on the above data, the highest position of the album “Tracks” in Canada is 50. - What year was “Highway Patrolman” released?
Based on the provided GraphQLResponse, “Highway Patrolman” was published in 1982.
who produced “all or nothing?”
6.2 Query format
The code contains a function to add additional instructions to the query. As you probably noticed, this functionality is not used. Let’s see what happens when you remove this from the query. The createPrompt the method becomes the following (I haven’t removed everything so only a minor code change is required).
private static String createPrompt(String question, String inputData, String extraInstruction)
return "Answer the following question: " + question + "\n" +
"Use the following data to answer the question: " + inputData;
Running the code adds some additional information to the answer to question 3 which is not entirely correct. It is true that the album has chart positions for the United States, the United Kingdom, Germany and Sweden. It is not true that the album reached the top 10 in the British and American charts. All other questions were answered correctly.
- What is the highest position of the album “Tracks” in Canada?
Based on the above data, the highest position of the album “Tracks” in Canada on the chart is not specified. The data only includes chart positions for other countries such as the United States, the United Kingdom, Germany, and Sweden. However, the album reached the top 10 in the UK and US charts.
It remains a bit brittle when using LLM. You can’t always trust the answer that is given. It seems that an appropriate change to the query is possible to minimize the LLM hallucinations. Therefore, it is important that you collect feedback from your users to recognize when LLM is hallucinating. In this way, you will be able to improve the responses to users. Fiddler has written an interesting blog that addresses this type of problem.
7. Conclusion
In this blog you learned how to implement RAG using Weaviate, LangChain4j and LocalAI. The results are quite amazing. Embedding documents in the right way, filtering the results and sending them to LLM is a very powerful combination that can be used in many use cases.