Ready to get started with a cloud native observation capability with telemetry pipelines?
This article is part of a series exploring a workshop that walks you through the Fluent Bit open source project, what it is, basic installation, and setting up your first telemetry project. Learn how to manage your native cloud data from source to destination using telemetry pipeline stages that cover collection, aggregation, transformation, and forwarding from any source to any destination.
Since Chronosphere gained the capabilities to integrate telemetry pipelines, I’ve been exploring how this works, the use cases it solves, and I’ve been having a lot of fun with the foundation, the CNCF Fluent Bit project. This workshop is the result of me sharing with you how to get started with telemetry pipelines and what you can do with Fluent Bit.
This first article in the series is an introduction to Fluent Bit where we gain an understanding of its role in the world of cloud native visibility. You can find more details in the accompanying laboratory of the workshop.
Before we begin, let’s lay the groundwork for defining a cloud-native observation pipeline. As noted in a recent trend report:
Observation pipelines enable real-time filtering, enrichment, normalization and routing of telemetry data.
The increase in the amount of data being generated in cloud native environments has become a huge burden on the teams trying to manage it all, as well as a burden on the organization’s budgets. They want more control over all this telemetry data, from collection, processing and routing, to storage and querying.
Data pipelines have become more important in helping organizations meet the challenges they face by providing a powerful way to reduce input and reduce data costs.
One benefit is that telemetry pipelines act as a telemetry gateway between cloud-native data and organizations. They perform real-time filtering, enrichment, normalization and routing to low-cost storage. This reduces dependence on expensive and often proprietary storage solutions.
Another plus for organizations is the ability to reshape collected data on the fly, often bridging the gap between legacy or non-standard data structures versus current standards. They can achieve this without having to update code, re-instrument or redeploy existing applications and services.
Telemetry pipelines
This workshop is focused exclusively on Fluent Bit as an open source telemetry pipeline project. From the project documentation, Fluent Bit is an open source telemetry agent specifically designed to effectively address the challenges of collecting and processing telemetry data in a wide range of environments, from constrained systems to complex cloud infrastructures. It is efficient in managing telemetry data from various sources and formats can be a constant challenge, especially when performance is a critical factor.
While the term “observation pipelines” is used to cover all kinds of general pipeline activities, the focus of this workshop will be more on telemetry pipelines. This is due to our focus on getting all different types of telemetry from their sources to their intended destinations, and as stated in the aforementioned trend report:
Telemetry pipelines enable real-time filtering, enrichment, normalization and routing of telemetry data.
Rather than serving as a replacement, Fluent Bit enhances the visibility strategy for your infrastructure by customizing and optimizing your existing logging layer, as well as metrics and tracking processing. Furthermore, Fluent Bit supports a vendor-neutral approach, seamlessly integrating with other ecosystems such as Prometheus and OpenTelemetry.
Fluent Bit can be deployed as an edge agent for localized telemetry data handling or used as a central aggregator or collector to manage telemetry data across multiple sources and environments. Fluent Bit is designed for performance and low resource consumption.
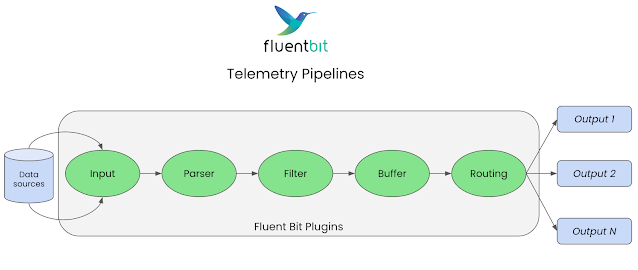
As a telemetry pipeline, Fluent Bit is designed to process records, metrics and traces with speed, scale and flexibility.
What about Fluentd?
First, there is Fluentd, CNCF’s graduate project. It is an open source data collector for building a unified logging layer. Once installed, it works in the background to collect, analyze, transform, analyze and store various types of data.
Fluent Bit is a sub-project within the Fluentd ecosystem. It is considered a lightweight data forwarder for Fluentd. Fluent Bit is specifically designed to pass data from the edge to the Fluentd aggregator.
Both projects share similarities. Fluent Bit is completely designed and built on top of the best ideas of Fluentd architecture and general design:

Understanding concepts
Before we dive into using Fluent Bit, it’s important to understand the key concepts, so let’s explore the following:
- Event or record: Each incoming data is considered an event or a record.
- Filtering: The process of changing, enriching or discarding events
- To mark: An internal string used by the router in later stages of our pipeline to determine which filters or output stages the event must pass through
- Time stamp: It is assigned to each event as it enters the pipeline and is always present
- Matching: Represents a rule applied to events where it checks for matches of its tags
- Structured message: The goal is to ensure that all messages have a structured format, defined to have keys and values.
Pipeline stages
A telemetry pipeline is where data goes through various stages from collection to final destination. We can define or configure each stage to manipulate the data or the path it takes through our telemetry pipeline.
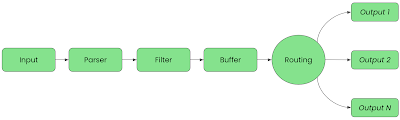
The first phase is INPUT, where Fluent Bit uses input plugins to gather information from specific sources. When an input plugin is loaded, an instance is created that we can configure using the plugin properties.
It’s the second phase PARSE, where unstructured input data is converted into structured data. Fluent Bit does this by using parsers that we can configure to manipulate unstructured data producing structured data for the next stages of our pipeline.
The FILTER phase is when we change, enrich or delete any of the collected events. Fluent Bit provides many out-of-the-box plugins such as filters that can match, exclude or enrich your structured data before it goes further into the pipeline. Filters can be configured using the properties provided.
The BUFFER stage is where the data is stored, using in-memory or filesystem-based options. Note that when the data reaches the buffer stage it is in an immutable state (no more filtering) and that the data in the buffer is not raw text but in an internal binary storage representation.
The next stage is ROUTING, where Fluent Bit uses the previously discussed tag and match concepts to determine which output destinations to send data to. During the input phase, the data is assigned a label; during the routing phase the data is compared to the matching rules from the output configurations. If it matches, then the data is sent to that output destination.
It’s the final stage EXIT, where Fluent Bit uses output plugins to connect to specific destinations. These destinations can be databases, remote services, cloud services, and more. When an input plugin is loaded, an instance is created that we can configure using the plugin properties.
For code examples for these stages and more details on the stages of the telemetry pipeline, see the workshop lab.
What’s next?
This article was an introduction to telemetry channels and Fluent Bit. This series continues with the next step in this workshop: installing Fluent Bit on your local machine from source or using container images.
Stay tuned for more practical material to help you on your cloud watching journey.