Both monitoring and visibility are critical in DevOps.
Because it allows you to maintain system reliability, diagnose problems and improve performance, efficiently and effectively.
For DevOps, this is the essence of monitoring and observation.
- Surveillance is for computers; perceptibility is for humans.
- Tracking is data collection; the observation is that it makes sense.
- Observability is about the “why”, while monitoring is about the “what”.
- Monitoring is necessary, but observation is indispensable.
- In the world of systems, tracking is the starting point, but visibility is the destination.
- Observability is the key to unlocking the mysteries of distributed systems.
How do cutting-edge digital products use visibility and control for engineering excellence?
Observability and monitoring have become essential components in ensuring the reliability, performance and scalability of digital products.
Here’s how top digital products use visibility and tracking.
Netflix
Simplified eBPF performance optimization
Netflix recently announced the release of bpftop.
bpftop provides a dynamic representation of eBPF program execution in real time. Shows average execution time, events per second and estimated total CPU % for each program.
This tool reduces overhead by allowing performance statistics only when in use.
Without bpftop, optimization tasks would require manual calculations, unnecessarily complicating the process.
But with bpftop it’s easier. You can see where you started, improve things and check if they really got better, all without any extra hassle. (Source)
Improved alerting with Atlas Streaming Eval
Netflix has shifted its alerting system architecture from traditional survey-based methods to real-time streaming evaluation.
This transition was driven by scalability issues when the number of configured alerts increased dramatically, causing delays in alert notifications.
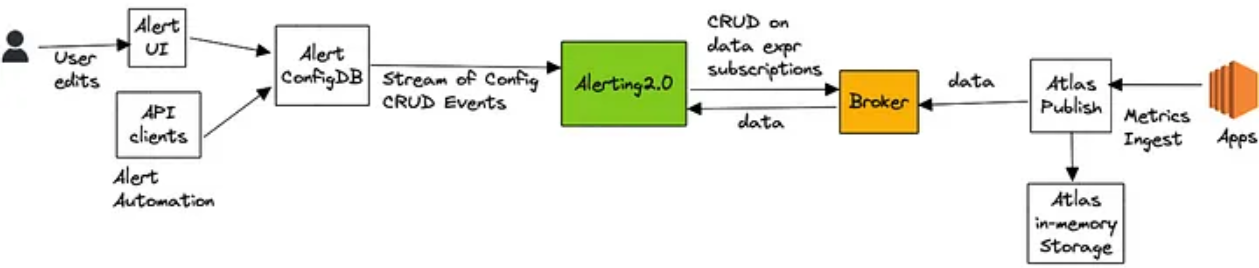
By leveraging streaming evaluation, Netflix has overcome the limitations of its time series database, Atlas, and improved scalability while maintaining reliability.
Key outcomes include accommodating a 20X increase in query volume, easing restrictions on high-cardinality queries, and improving application health monitoring with correlations between SLI metrics and custom metrics derived from log data.
This change opens the door to more effective alerts and advanced monitoring capabilities, although it requires overcoming challenges in debugging and matching the stream path to database queries.
Overall, the transition shows a significant improvement in Netflix’s viewing infrastructure. (Source)
Building Netflix’s distributed monitoring infrastructure
Edgar, a distributed monitoring infrastructure aimed at improving troubleshooting efficiency for streaming services.
Before Edgar, Netflix engineers faced challenges in understanding and resolving streaming failures due to the lack of context provided by traditional troubleshooting methods involving metadata and logs from various microservices.
Edgar addresses this by providing comprehensive distributed tracing capabilities, enabling the reconstruction of session streams by identifying session IDs.
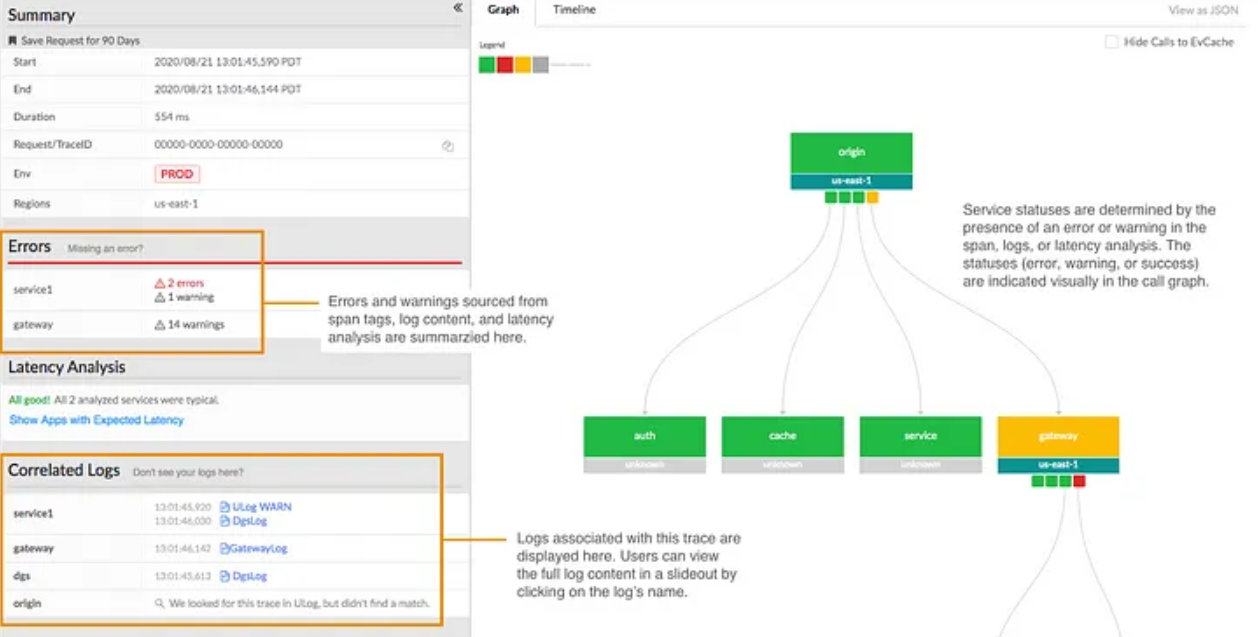
Using Open-Zipkin for tracing and Mantis for stream processing, Edgar enables collecting, processing and storing traces from different microservices.
Key components of Edgar include trace instrumentation for context propagation, stream processing for data sampling, and storage optimization for cost-effective data retention.
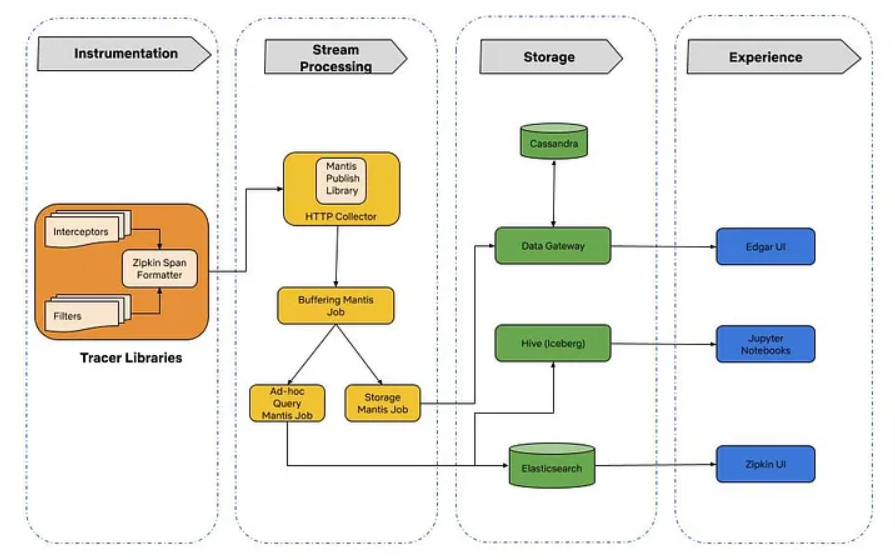
Through a hybrid head-based sampling approach and storage optimization strategies such as using cheaper storage options and using better compression techniques, Edgar optimizes resource utilization while ensuring efficient problem resolution.
In addition, Edgar’s monitoring data serves multiple use cases beyond troubleshooting, including application health monitoring, resilience engineering, regional evacuation planning, and infrastructure cost estimation for A/B testing.
In essence, Edgar significantly improves engineering productivity by providing a simplified and efficient method for solving flow-level fault problems. (Source)
Uber
Observability at Scale: Building Uber’s Alert Ecosystem
Uber’s alerting ecosystem is a vital component in maintaining the stability and scalability of its thousands of microservices.
The Observability team has developed two primary alerting systems: uMonitor, which focuses on metrics-based alerts, and Neris, which manages infrastructure alerts at the host level.
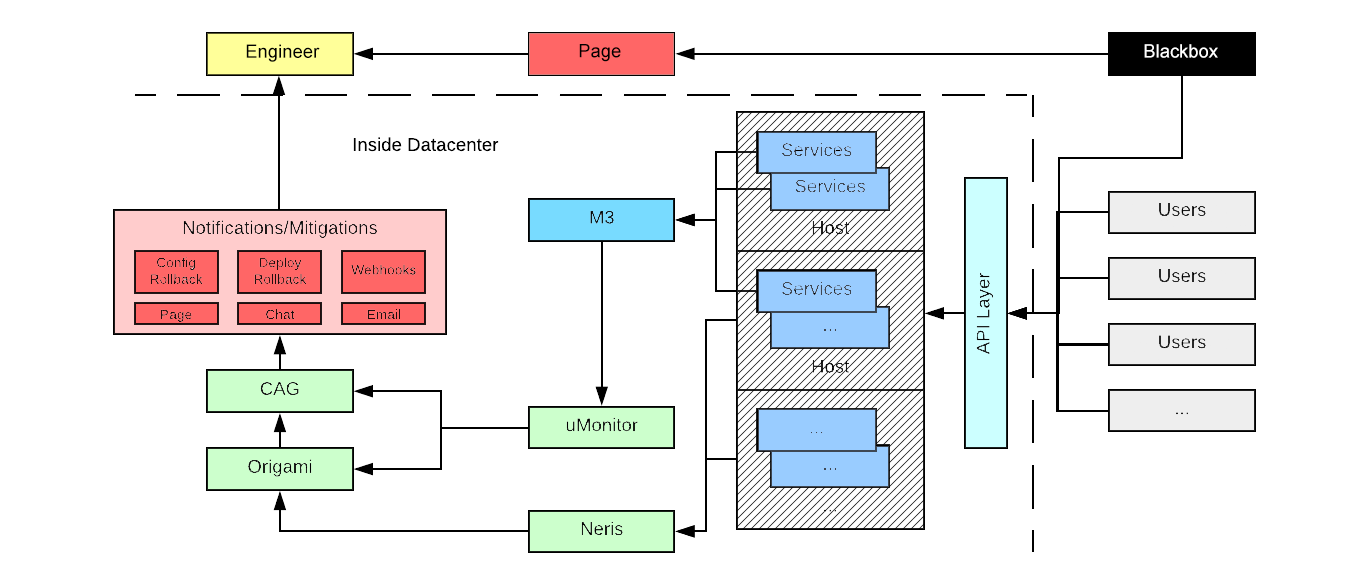
uMonitor runs on a flexible platform, enabling easy alert management and different use cases, while Neris executes alert checks directly on hosts to efficiently handle high-resolution and cardinality metrics.
Addressing high-cardinality challenges is central to Uber’s alerting approach.
Origami, a deduplication and notification engine, helps manage alerts by consolidating notifications and allowing aggregation of alerts based on different criteria such as city, product, or app version.
This helps reduce noise and provides relevant alerts to engineers.
Overall, Uber’s alerting ecosystem is tailored to the size and complexity of its infrastructure, with a focus on flexibility, scalability and notification relevance. (Source)
Uber’s big data tracking and refund platform
Uber’s data infrastructure consists of a wide range of computing engines, execution solutions and storage solutions.
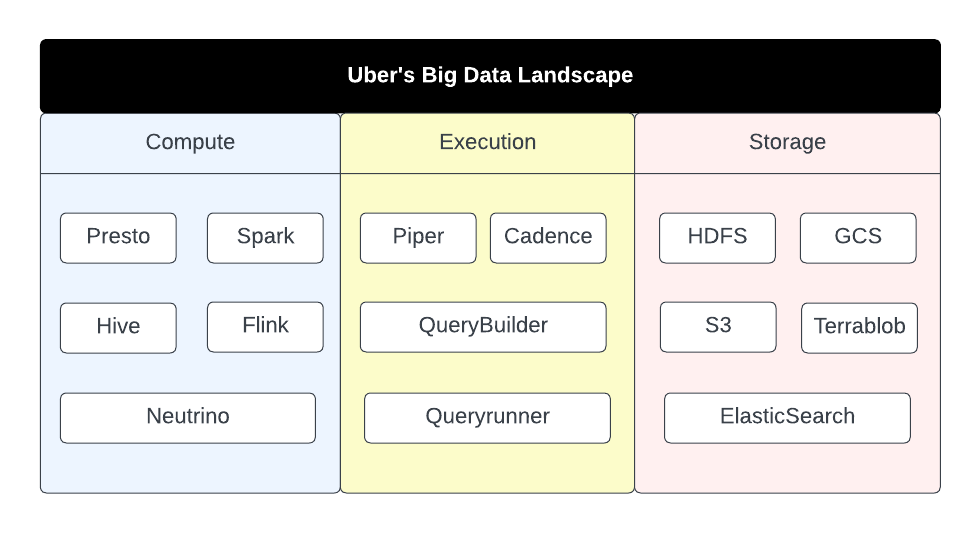
With such a complex and diverse data infrastructure, it is quite challenging to provide stakeholders with a holistic view of performance and resource consumption across different computing engines and storage solutions.
And that’s when DataCentral enters the scene.
It is a comprehensive platform that provides users with essential insights into big data applications and queries.
DataCentral helps data platform users by offering detailed information about workflows and applications, improving productivity and reducing debugging time.
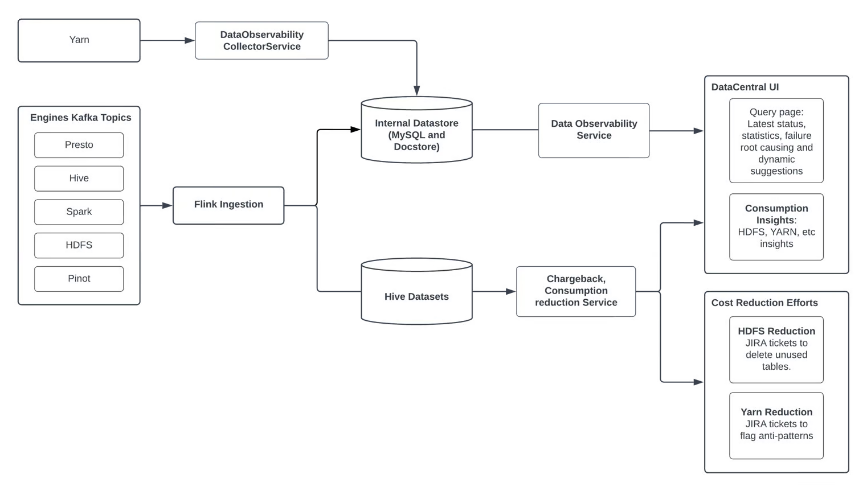
The following are the key features of DataCentral.
Noticeability
It provides precise insights into performance trends, costs and degradation signals for big data jobs.
Furthermore, DataCentral provides historical trends for metrics such as cost, duration, performance, data read/write, and churn, enabling faster discovery and debugging of applications.
Return
It tracks metrics and resource usage for big data tools and engines such as Presto, Yarn, HDFS and Kafka, enabling stakeholders to understand costs at different levels of granularity such as user, pipeline, application, schedule and queue level.
Spending reduction programs
DataCentral drives cost reduction initiatives by providing insight into expensive pipelines, declining workloads and unnecessary compute.
Contactless
A system focused on effectively troubleshooting failed queries and applications by improving error detection, identifying root causes, and providing easy-to-use explanations and suggestions.
Compares exception traces with rules set by engine teams to display relevant messages. (Source)
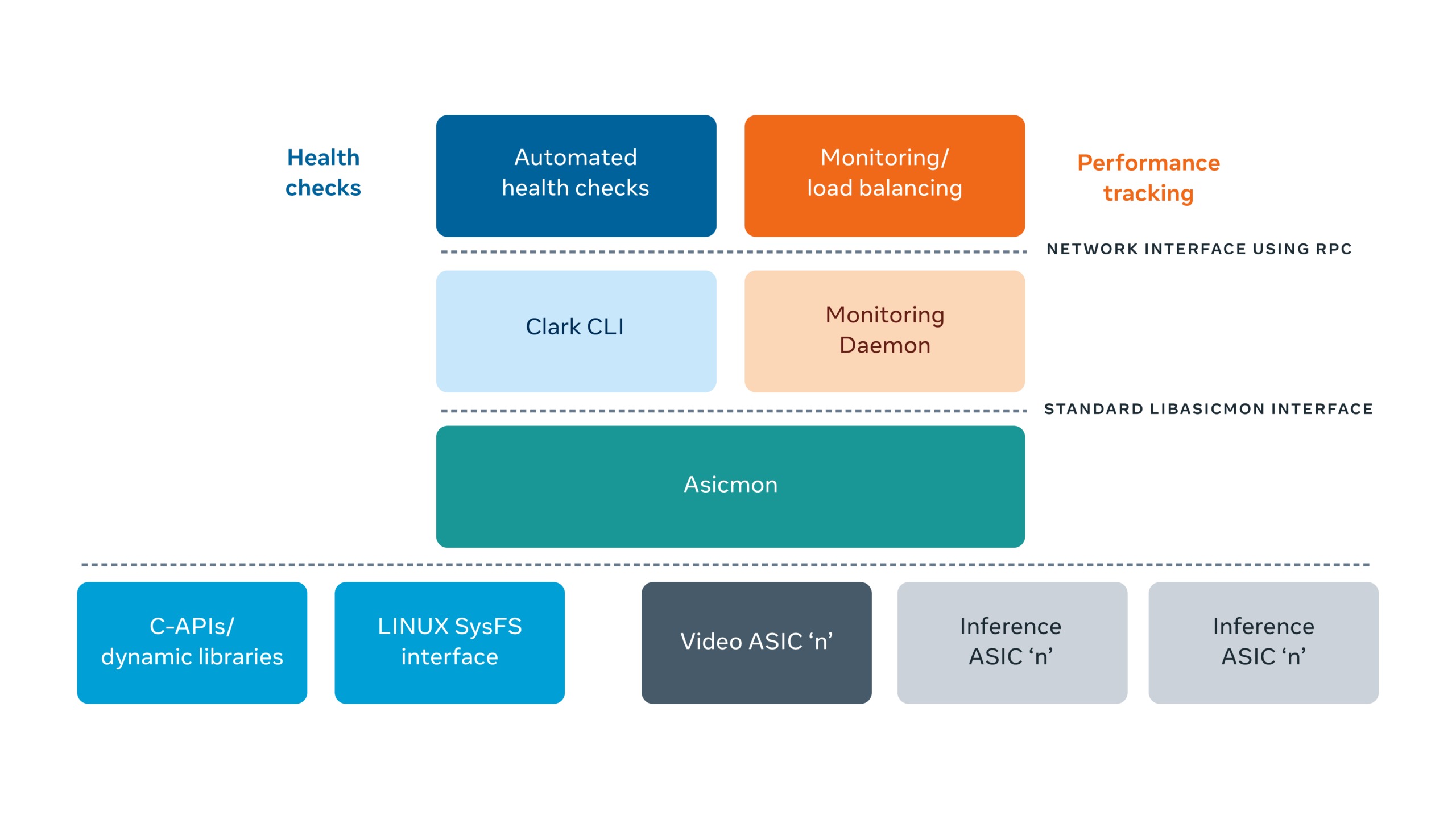
Asicmon: Platform Agnostic Observability System for AI Accelerators
Accelerators are like specialized tools for specific jobs, such as AI tasks or video work.
They are of great help in speeding up and running more energy efficiently, especially in Facebook’s data centers.
But handling all these different tools effectively is largely difficult.
To tackle these obstacles, Facebook introduced three innovative tools.
Asicmon (ASIC monitoring)
This scalable observation framework abstracts custom accelerator interfaces, offering a standardized interface to internal tools.
Asicmon facilitates load balancing, performance monitoring and automated health checks for the multitude of accelerators deployed in Facebook data centers.
Asimov
It is a custom specification language that guides the development and rapid prototyping of new accelerators.
By reducing the onboarding time for a new accelerator from a month to less than a week, Asimov significantly accelerates the innovation cycle.
Atrace
A trace accelerator solution that collects traces remotely on production servers.
Atrace provides an in-depth view of accelerator systems, providing trace summaries and actionable analysis.
In an initial implementation, Atrace helped reduce the performance gap of 10 percent between Caffe2 and PyTorch implementations of a large AI model.
Here is a diagram of how Asicmon acts as a bridge between the individual accelerator drivers and the rest of the internal monitoring software. (Source)