Are you watching your organization’s efforts to enter or expand into a cloud-native environment and feel a little overwhelmed by the overwhelming amount of information surrounding cloud-native visibility?
When you’re moving so quickly with agile practices in your DevOps, SRE, and platform engineering teams, it’s no wonder this can seem a little confusing.
Unfortunately, the choices made have a major impact on your business, your budgets, and the ultimate success of your cloud initiatives, as rash decisions up front lead to major headaches down the road.
In a previous article, we discussed why so many practitioners are underestimating their existing landscape within cloud monitoring solutions. In this article, I will share insights into the maze that is the protocol jungle and how it causes us pain. By sharing common pitfalls in this series, we hope we can learn from them.
We often get excited about the solutions we design and forget the fundamental decisions that are important for a long-term scalable solution. Open standards should be the default, but it’s obviously very easy to get lost in the protocol jungle when designing our cloud-native surveillance solutions.
Choosing the right path
The fundamental question is: will we keep our options open and apply open source in our observation architecture? While I’ve talked a lot throughout my career about how the default for me is always open, in the cloud native world it hasn’t always been possible to find open standards to apply.
When containers first broke into native cloud environments, the tools that were shipped did not follow any accepted standards. To solve this problem, the surrounding user community (and vendors) developed the Open Container Initiative (OCI) to ensure that all future implementations adhere to a common standard.
The same cycle continued with cloud native visibility and community gathering until today around a collection of projects under the Cloud Native Computing Foundation (CNCF). Although many vendors in the field of observation come from the second generation where application performance monitoring (APM) solutions were implemented using proprietary languages and protocols, the community quickly sought a path to standardization.
Needless to say, investing in a proprietary monitoring tool that uses closed standard protocols and questionable languages will only cause us pain. Possible prices and limitations in tool functionality encourage all organizations to constantly develop their solution architectures. When we’ve invested our time and extensive effort using proprietary implementations, migration issues can seem almost insurmountable.
Let Open guide your efforts
Many projects within the CNCF community have made efforts to standardize everything related to cloud native visibility. Although not all standards are certified, many are so universally applied that they are the unofficial standards of observation. Let’s take a look at some of these standards and discover why open standards are the best guides for your monitoring efforts.
Prometheus
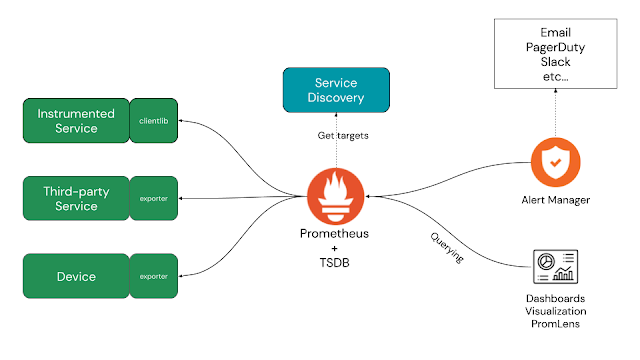
Prometheus is a graduate project under CNCF and is defined as “considered stable and in production use”. It’s listed as a monitoring system and time series database, but the project page itself advertises that it’s used to power your metrics and alerts with a leading open source monitoring solution.
.png)
Prometheus provides a flexible data model that allows you to identify time series data, which is a sequence of data points indexed in time order, by assigning a metric name. Time series are stored in memory and on local disk in an efficient format. Scaling is done by functional sharding, storage data sharding, and pooling.
The key standard here is that Prometheus uses a pull model to collect metrics, scraping targets that we define or that it can automatically detect. This provides us with a powerful way to integrate our existing application and service environment to collect viewability data.
Exploiting metric data is done with a very powerful query language, and the official project documentation states: “Prometheus provides a functional query language called PromQL (Prometheus Query Language) that allows the user to select and aggregate time series data in real time. The result of an expression can be displayed as chart, view as tabular data in the Prometheus Expression Browser, or be used by external systems via the HTTP API.”
Interested in getting started with Prometheus and PromQL? Both can be explored in this free online workshop.
OpenTelemetry
This project, also known as OTel, is a fast-growing project with a focus on “high-quality, ubiquitous and portable telemetry that enables effective visibility.”
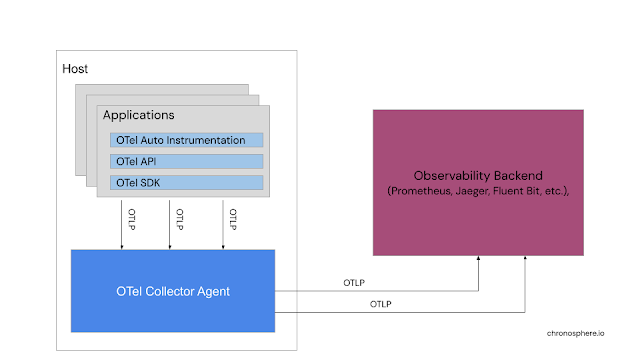
This project helps us generate telemetry data from our applications and services, passing it to what is now considered a standard known as the OpenTelemetry Protocol (OTLP), to various monitoring tools. To generate telemetry data, you must first instrument your code, but OTEL makes it very easy with automatic instrumentation through integration with many existing languages.
Two things are worth noting here.
One is that OTel works by pushing telemetry data from our applications and services to OTel using collection agents on the host computer. This means that every application or service sends telemetry data that we have instrumented to use OTLP not only to Otel Collector, but also accepted into our chosen backend storage platform.
.png)
Another thing to note is that OTel does not provide a backend storage or query language, but instead provides standard OTLP for existing backend platforms. This is one of the great values of using the standard so that we can modify our back-end observator without breaking if it supports OTLP.
Fluent Bit
As stated in the official documentation, “Fluent Bit is an open source telemetry agent specifically designed to effectively address the challenges of collecting and processing telemetry data in a wide range of environments, from constrained systems to complex cloud infrastructures. Managing telemetry data from various sources and formats can be a constant challenge, especially when performance is a critical factor.”
More than just a collector, this is capable of customizing and optimizing existing logging layers as well as metrics and trace processing. As a CNCF project, it is designed to seamlessly integrate with other platforms such as Prometheus and OpenTelemetry. Fluent Bit uses standard TCP and HTTP for its outputs with vendors able to add plugins for their proprietary protocols and works with common data structures.
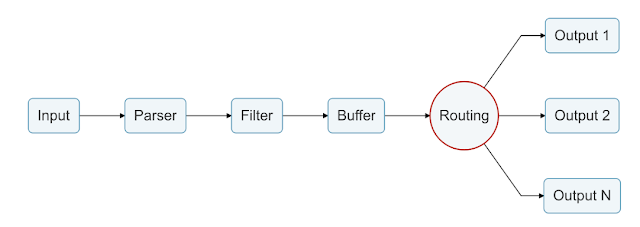
This is used for what is known as a data pipeline, which can receive, analyze, filter, persist and route to as many destinations as needed.
These are just a few examples of how we can keep our cloud native observation capabilities open and not get lost in the jungle of proprietary protocols. The path to success in cloud native has enough pitfalls and understanding how to avoid proprietary paths will save a lot of wasted time and energy.
Coming up
Another pitfall organizations struggle with in cloud native visibility is the hidden clutter of tools. In the next article in this series, I’ll share why this is a pitfall and how we can avoid it wreaking havoc on our cloud observing efforts.